

《鱼书》笔记
1. python基础
1.1 Numpy
Np的广播:
>>> x = np.array([1.0, 2.0, 3.0])
>>> x / 2.0
array([ 0.5, 1. , 1.5]) 多维数组:
>>> A = np.array([[1, 2], [3, 4]])
>>> print(A)
[[1 2]
[3 4]]
>>> A.shape #多维数组每项长度一样否则报错
(2, 2)
>>> A.dtype #矩阵元素的数据类型
dtype('int64')
>>> B = np.array([[3, 0],[0, 6]])
>>> A + B
array([[ 4, 2],
[ 3, 10]])
>>> A * B # *号为直接数组对应元素乘积
array([[ 3, 0],
[ 0, 24]]) 访问操作:
>>> X = np.array([[51, 55], [14, 19], [0, 4]])
>>> X = X.flatten() # 将X转换为一维数组, 即拉平
>>> print(X)
[51 55 14 19 0 4]
>>> X[np.array([0, 2, 4])] # 获取索引为0、2、4的元素
array([51, 14, 0]) 矩阵乘积(点乘):
>>> A = np.array([[1,2], [3,4]])
>>> A.shape
(2, 2)
>>> B = np.array([[5,6], [7,8]])
>>> B.shape
(2, 2)
>>> np.dot(A, B)
array([[19, 22],
[43, 50]])1.2 Matplotlib
import numpy as np
import matplotlib.pyplot as plt
# 生成数据
x = np.arange(0, 6, 0.1) # 以0.1为单位,生成0到6的数据
y = np.sin(x)
# 绘图
plt.plot(x, y)
plt.show()x = np.arange(0, 6, 0.1) # 以0.1为单位,生成0到6的数据
y1 = np.sin(x)
y2 = np.cos(x)
# 绘制图形
plt.plot(x, y1, label="sin")
plt.plot(x, y2, linestyle = "--", label="cos") # 用虚线绘制
plt.xlabel("x") # x轴标签
plt.ylabel("y") # y轴标签
plt.title('sin & cos') # 标题
plt.legend() #图例显示, 收集plot()中的label
plt.show() 显示图像:
import matplotlib.pyplot as plt
from matplotlib.image import imread
img = imread('lena.png') # 读入图像(设定合适的路径!)
plt.imshow(img)
plt.show()2. 感知机
2.1 什么是感知机
感知机算法是美国学者Frank Rosenblatt在1957年提出来的, 是神经网络的起源算法.
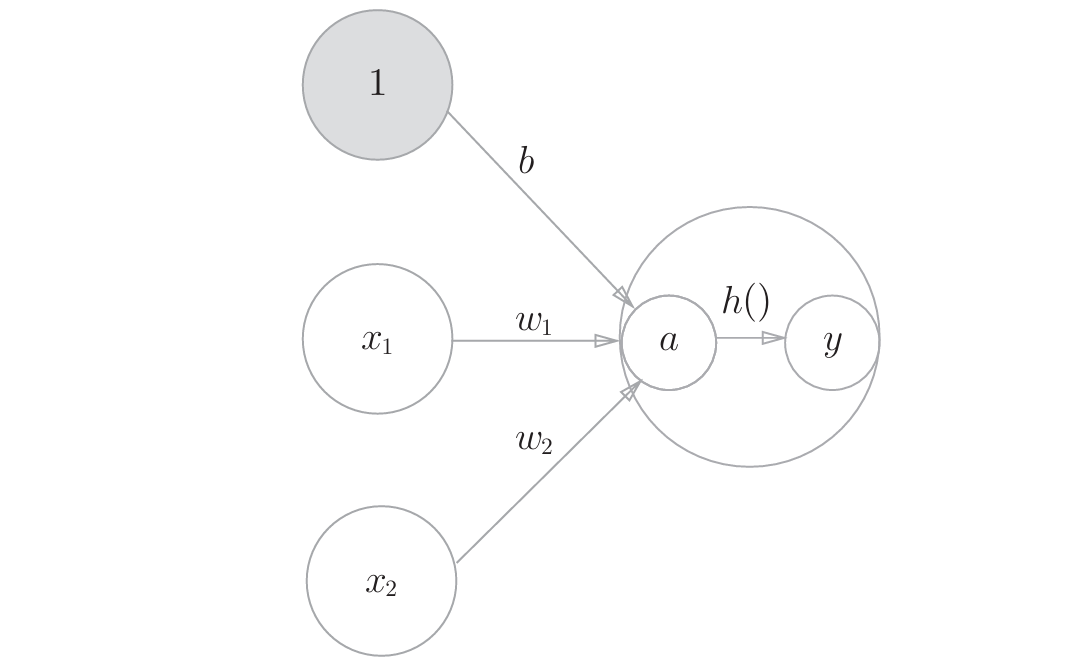
感知机接收多个输入信号, 输出一个信号. 在感知机中, ==输出信号==只有 0/1 两种取值. 为方便理解, 0对应"不传递信号", 1对应"传递信号".
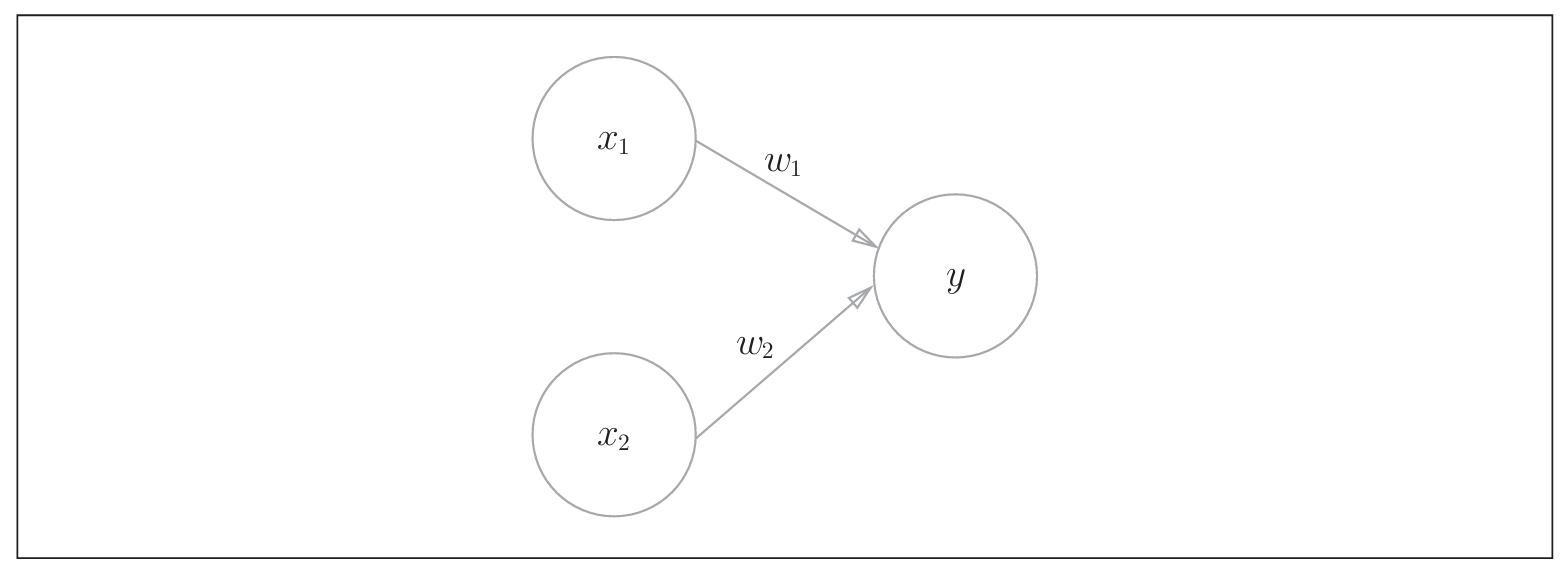
其中x~1~, x~2~为输入信号, w~1~, w~2~为权重. 图中圆圈称为"神经元"或者"节点". 输入信号被送往神经元时, 会分别乘以固定的权重. 这些信号的总和超过阈值 θ 时, 才会输出1, 称之为"神经元被激活". 即:
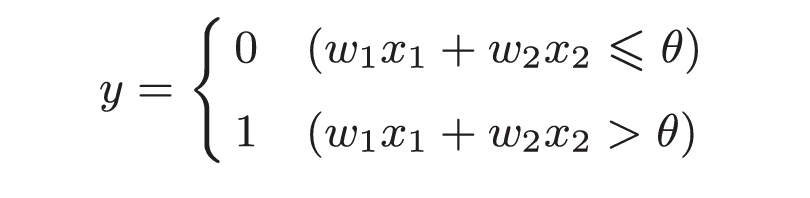
令θ = -b, 则有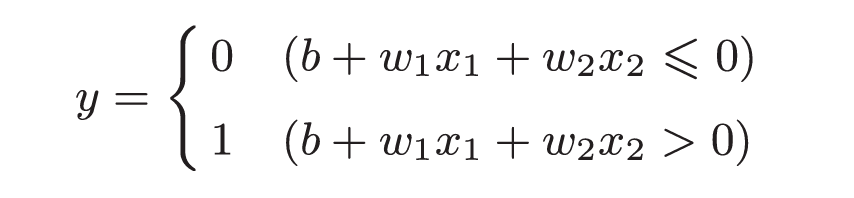
把b成为偏置, 把w~1~, w~2~称为权重
w~1~, w~2~为控制输入信号重要性的参数, 偏置是调整神经元被激活的容易程度的参数.
2.2 感知机的局限性
用上文中的感知机模型无法实现异或门, (w~1~, w~2~ + b> 0, 与w~1~ + w~2~ + b< 0矛盾)
2.2.1 线性与非线性
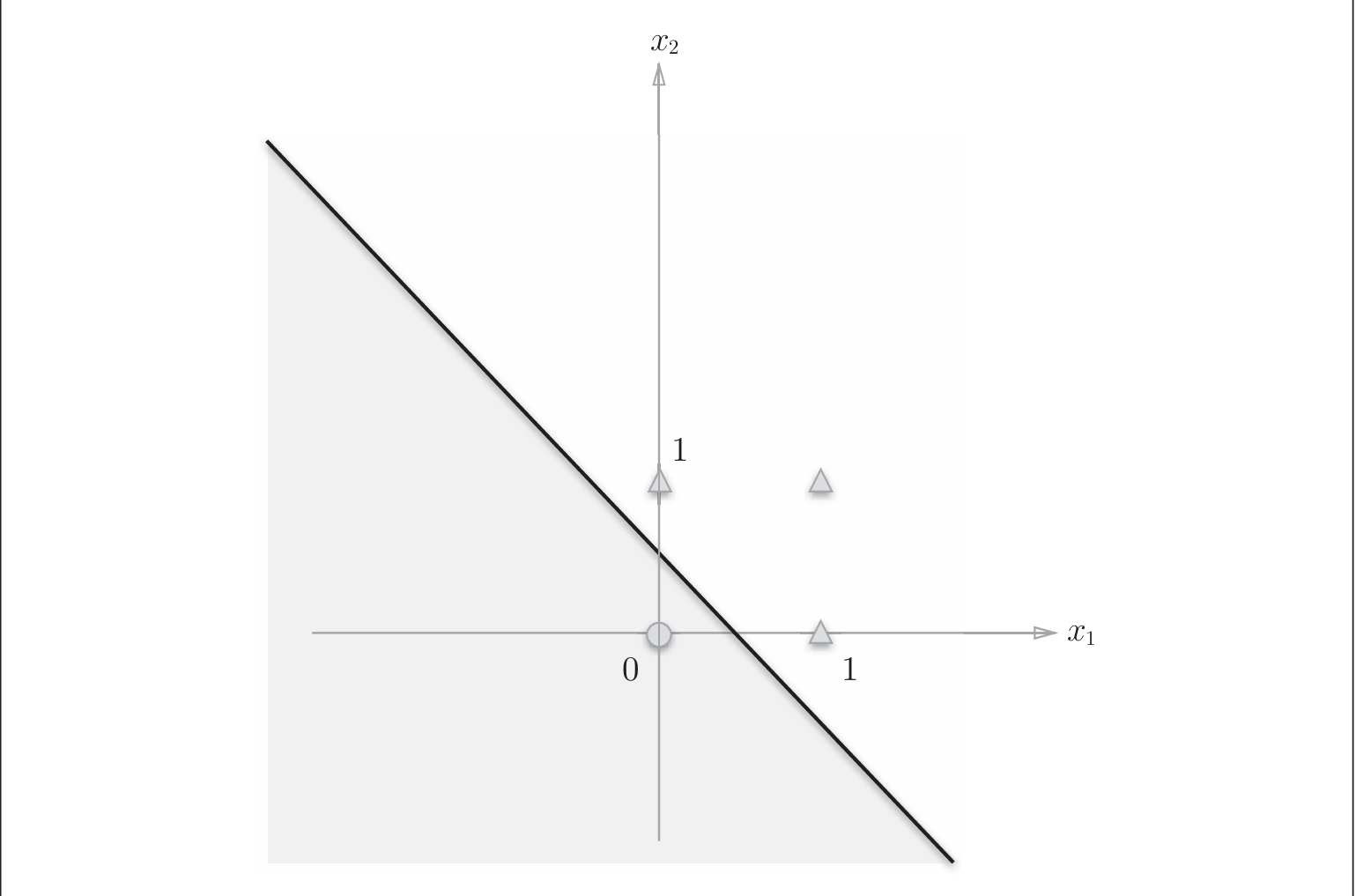
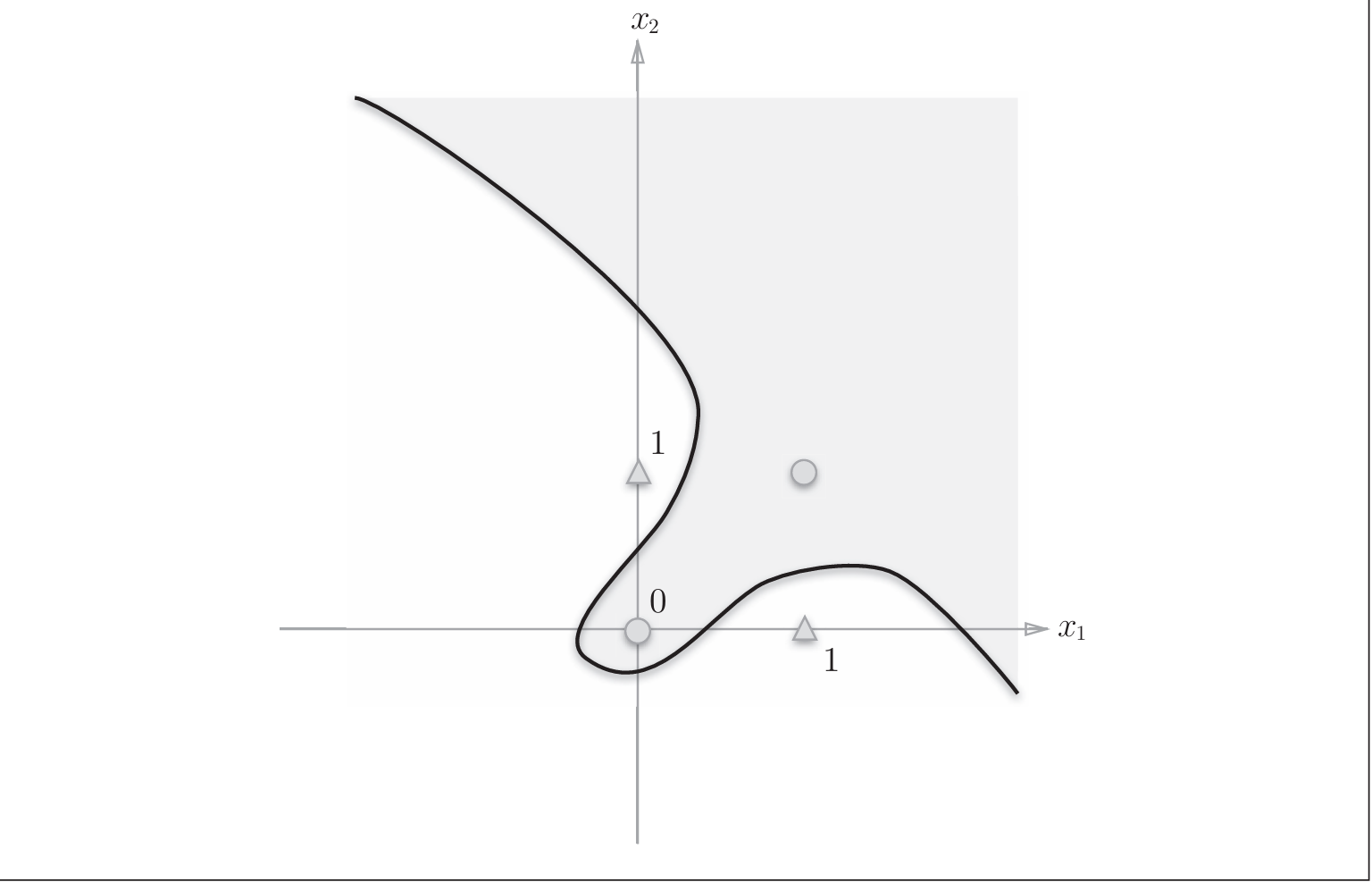
2.3 多层感知机 (异或门实现)
感知机的叠加, 使得感知机能够实现更多的功能, 如下图: 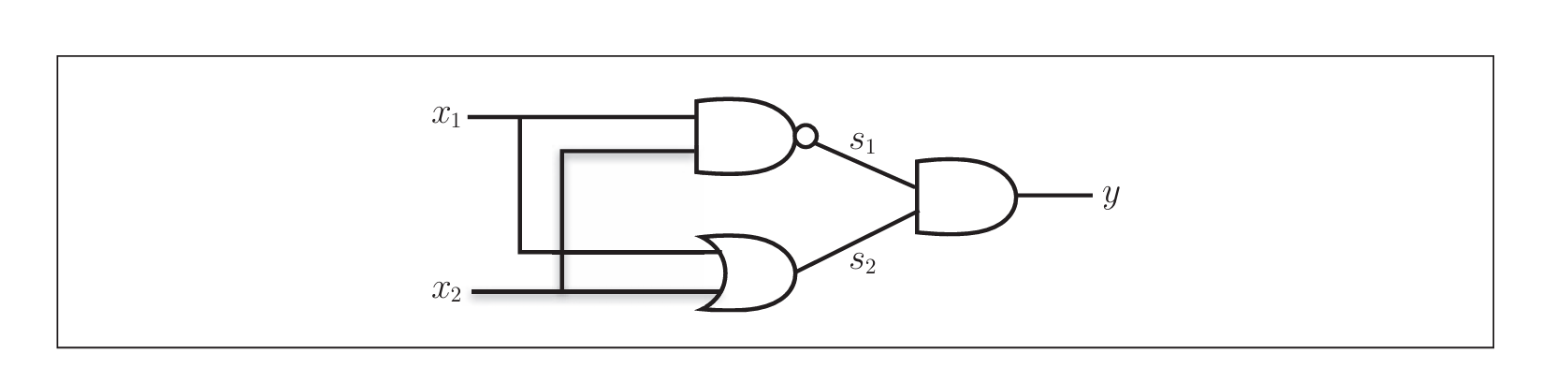
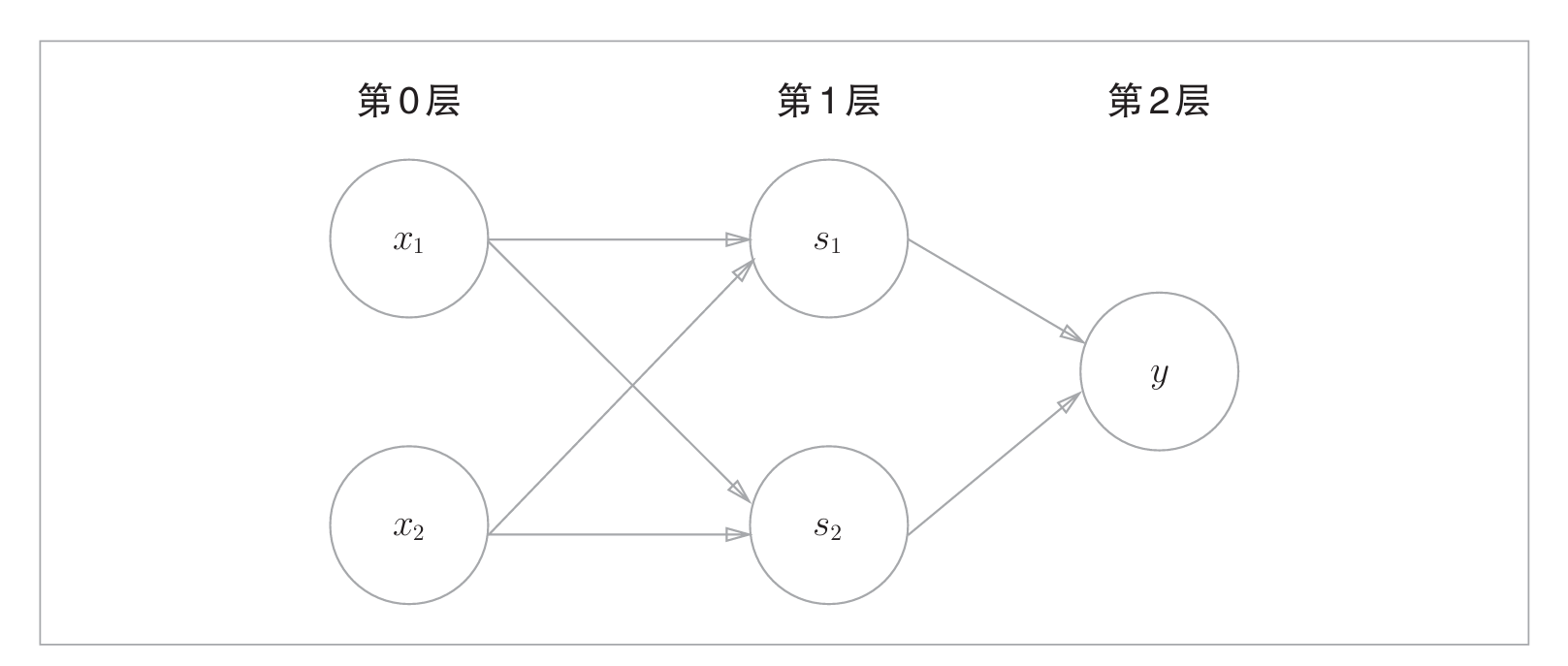
3.神经网络
神经网络的出线, 可以自动地从数据中学习到合适的权重参数.
3.1 神经网络的结构
输入层 ---- 隐藏层(中间层) ---- 输出层
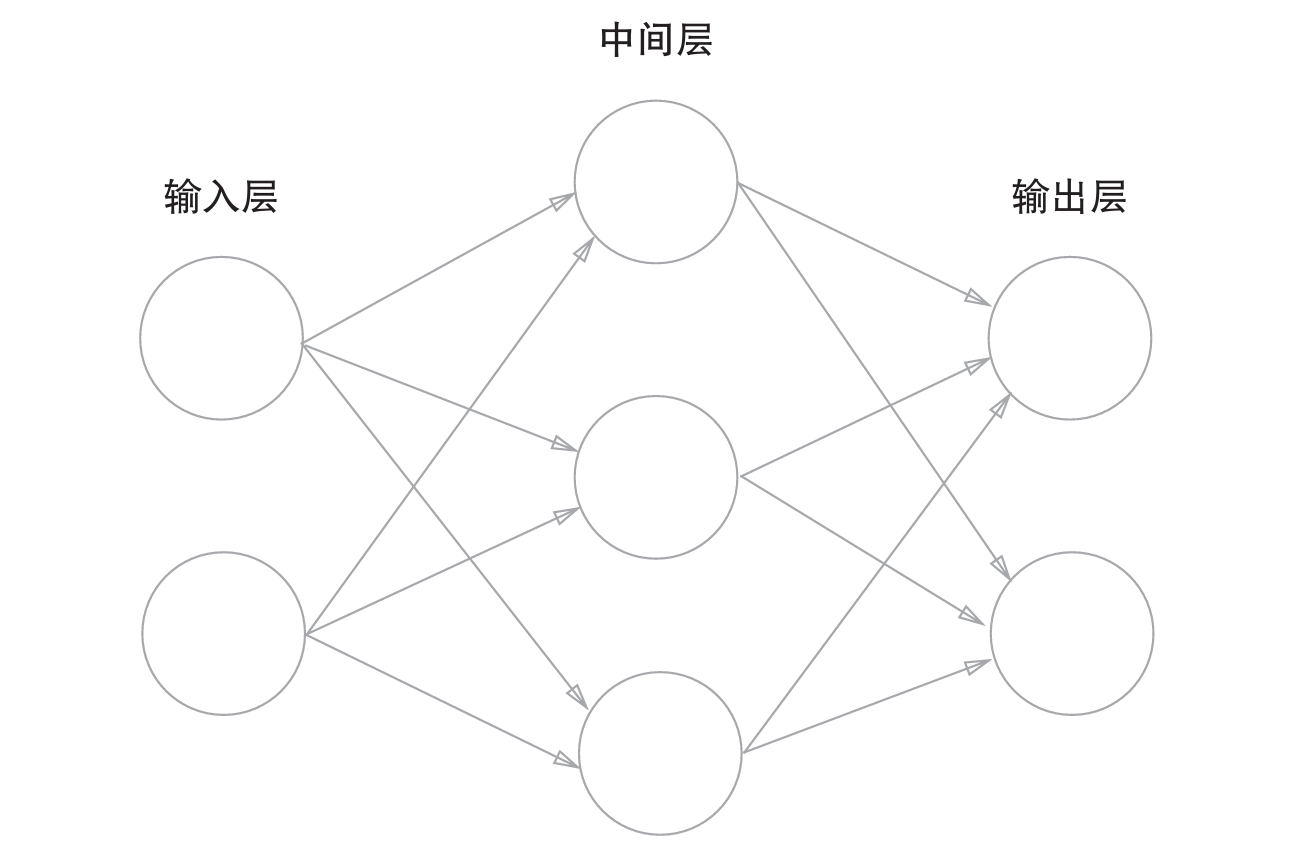
3.2 激活函数
激活函数: 将输入信号总和转化为输出信号的函数. 即下图中h(x):
3.2.1 阶跃函数
前文中的激活函数称为阶跃函数, 一旦输入超过阈值, 就切换输出.
3.2.2 sigmoid函数
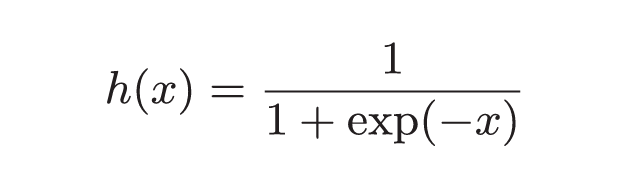
激活函数必须使用非线性函数, 因为如果使用线性函数的话, 那么叠加层就没有意义了
3.2.3 ReLU(Rectified Linear Unit)函数
ReLU函数, 输入大于0, 直接输出该值; 输入小于等于0时, 输出0.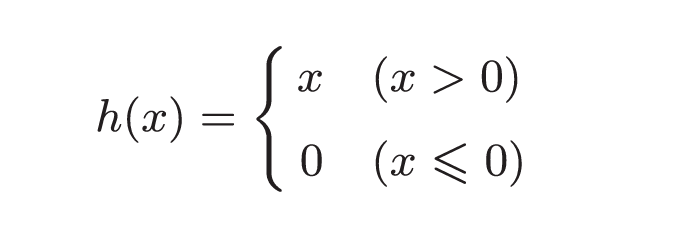
3.3 3层神经网络的实现
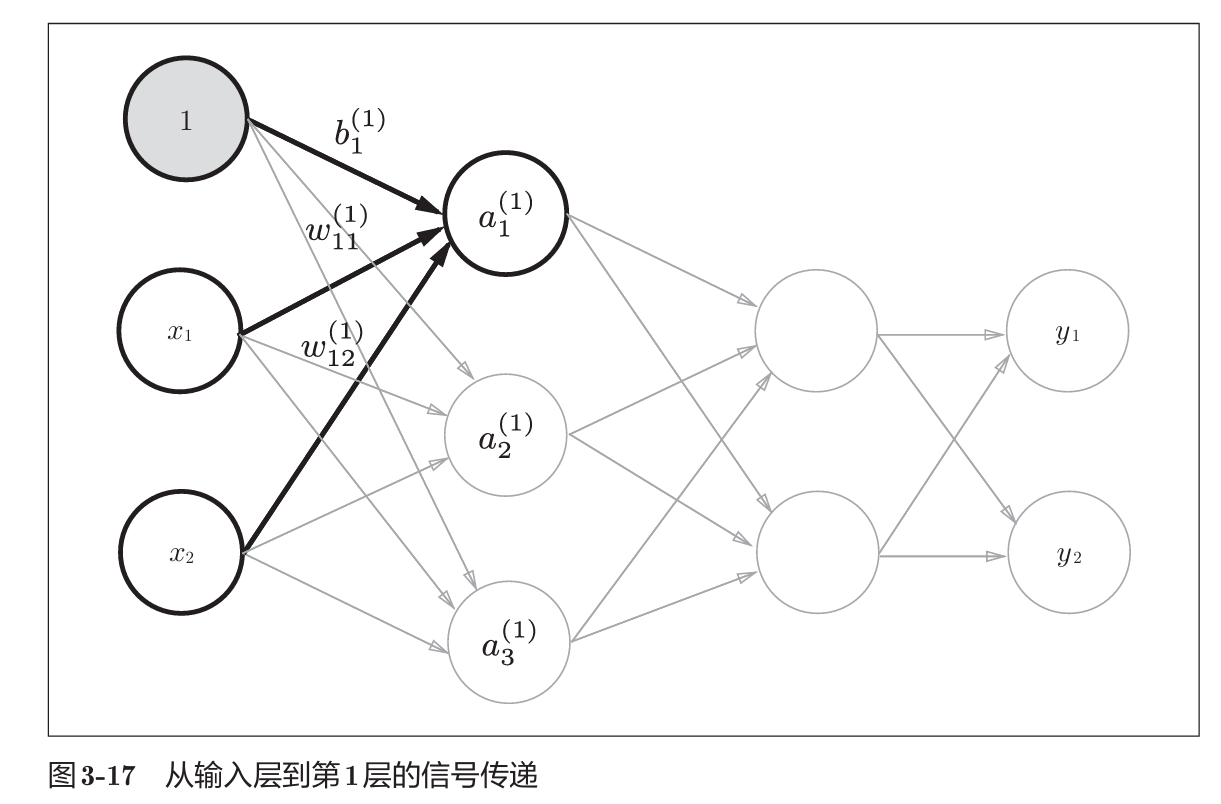
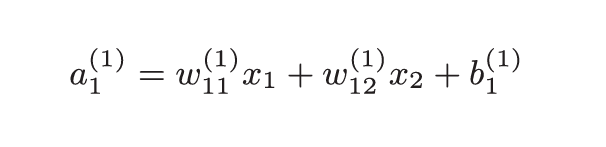
第一层的加权和可以表示为: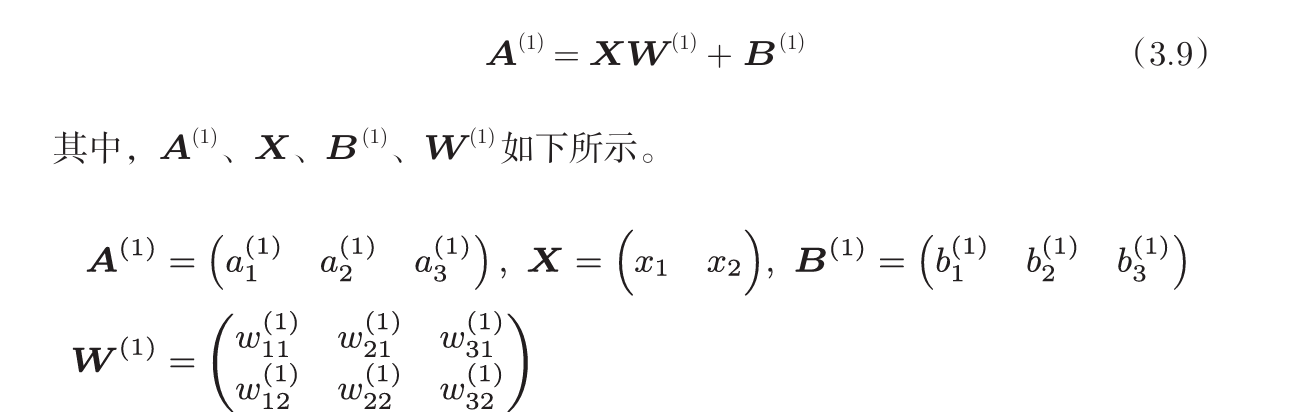
上述操作计算出了加权信号与偏置之和, 然后还要通过之前学习的激活函数转换为输出信号.
代码实现如下:
def step_function(x):
return np.array(x > 0, dtype=int)
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def relu(x):
return np.maximum(0, x)
def identity_function(x): #恒等函数
return x
def init_network(): #三层神经网络
network = {}
network['W1'] = np.array([[0.1,0.3,0.5], [0.2, 0.4, 0.6]])
network['b1'] = np.array([0.1, 0.2, 0.3])
network['W2'] = np.array([[0.1,0.4], [0.2, 0.5], [0.3, 0.6]])
network['b2'] = np.array([0.1, 0.2])
network['W3'] = np.array([[0.1,0.3], [0.2, 0.4]])
network['b3'] = np.array([0.1, 0.2])
return network
def forward(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, W3) + b3
y = identity_function(a3)
return y
network = init_network()
x = np.array([1.0, 0.5])
y = forward(network, x)
print(y)3.4 输出层设计
一般来说, 回归问题用恒等函数, 分类问题用softmax函数
3.4.1 softmax函数
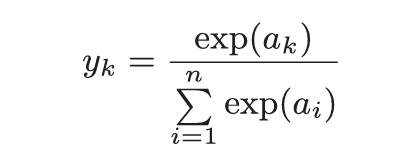
由于在计算机中, exp容易溢出, 所以需要对softmax函数进行改进
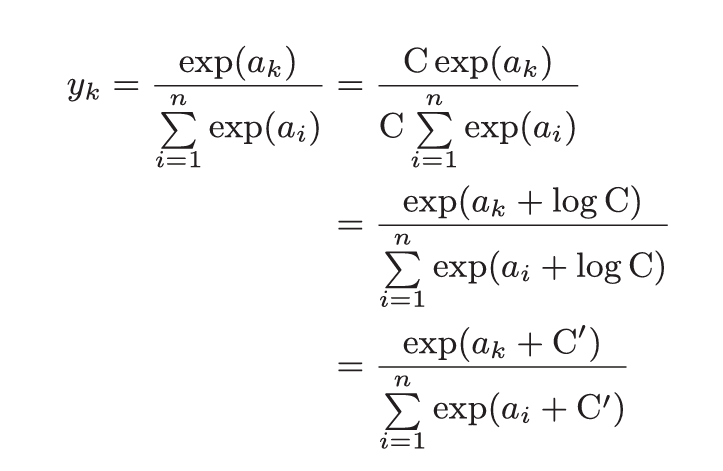
可以观察到, y~k~的和为1, 我们可以把softmax的输出解释为概率, 所以一般用于分类模型中, 一般而言, 神经网络只把输出值最大的神经元对应的类别作为识别结果. 且exp为递增函数, 故在进行推理阶段时, softmax函数可以省略.
3.5 MNIST数字识别
略
4. 神经网络的学习
机器学习的最终目标是获得泛化能力, 泛化能力是指处理未被观察过的数据的能力.
如果只对特定数据集处理能力好, 称为过拟合
4.1 损失函数
神经网络以某个指标为线索寻找最优的权重参数, 神经网络的学习中这个指标称为损失函数
损失函数 是表示神经网络性能的"恶劣程度"的指标, 即当前的神经网络对监督数据在多大程度上不拟合, 不一致.
4.1.1 均方误差
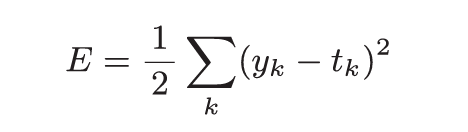
4.1.2 交叉熵误差
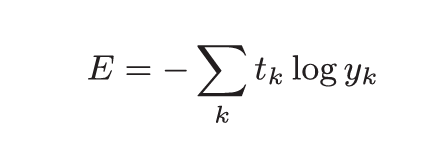
在one-hot表示中, t~k~只有正确解的标签为1, 所以实际上交叉熵误差的值由正确解标签所对应的输出结果决定.
在代码实现中, 为了防止 ln0 爆Inf, 所以可以添加一个微小值进行保护:
def cross_entropy_error(y, t):
delta = 1e-7
return -np.sum(t * np.log(y + delta))4.1.3 mini-batch学习
上述函数均为针对单个数据的损失函数, 如果要求所有训练数据的损失函数的总和, 以交叉熵误差为例, 可以写成下式.
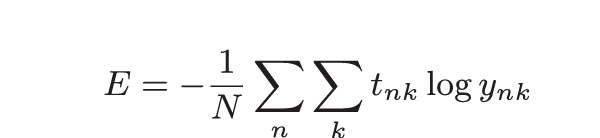
如果遇到数据量大的情况, 计算全部数据的误差和是不现实的. 因此, 我们可以从全部数据中选出一部分, 作为全部数据的"近似". 神经网络的学习也是从训练数据中选出一批数据(称为mini-batch, 小批量), 然后对每个mini-batch进行学习. 这种方式称为mini-batch学习.

4.2 梯度
机器学习中优化问题最常用的方法就是梯度下降法, 用于减小损失函数的值.

4.3 学习算法的实现

上图为书中初始化权重的函数, 可以发现在生成权重w时在随机生成后还乘以了一个weight_init_std, 这是由于sigmoid函数的特性, 在0和1处无法训练的问题.
超参数: 需要先手动设定的参数, 如权重, lr, 循环次数等
5. 误差反向传播法
5.1 反向传播链式法则
5.1.1 计算图
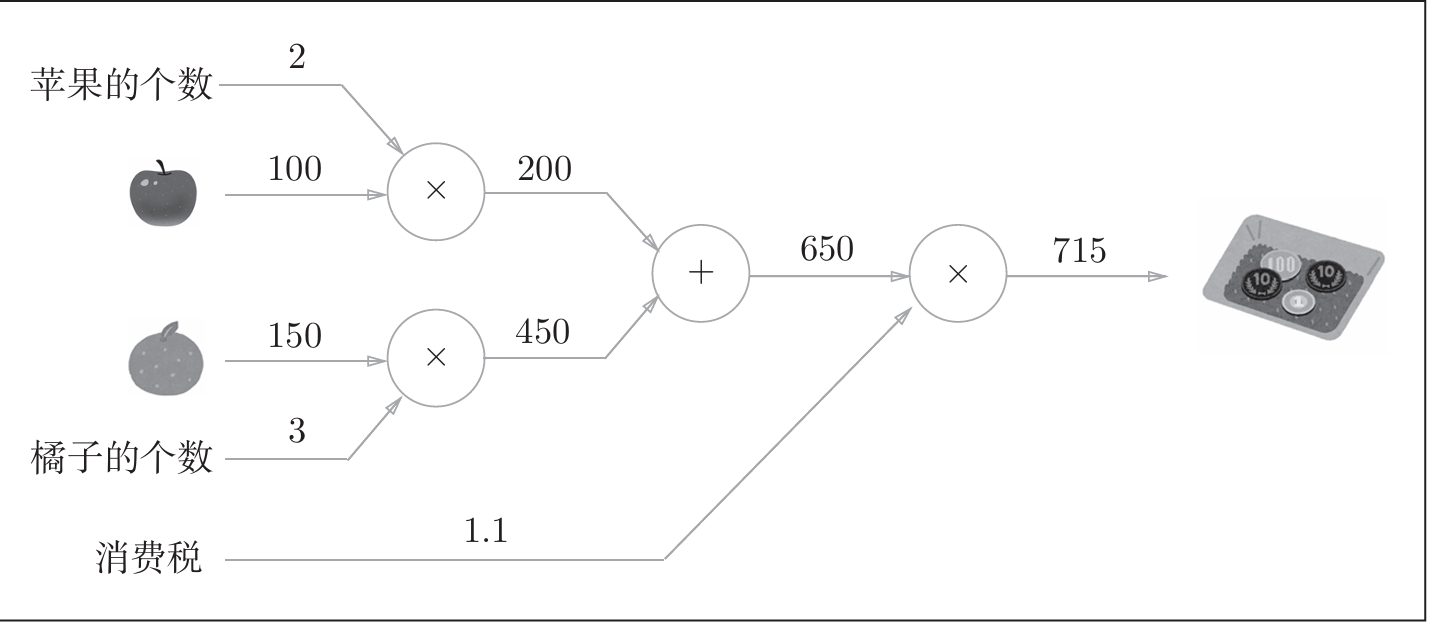
计算图可以集中精力于局部计算, 通过传递局部计算的结果, 可以获得全局的复杂计算结果
5.1.2 反向传播
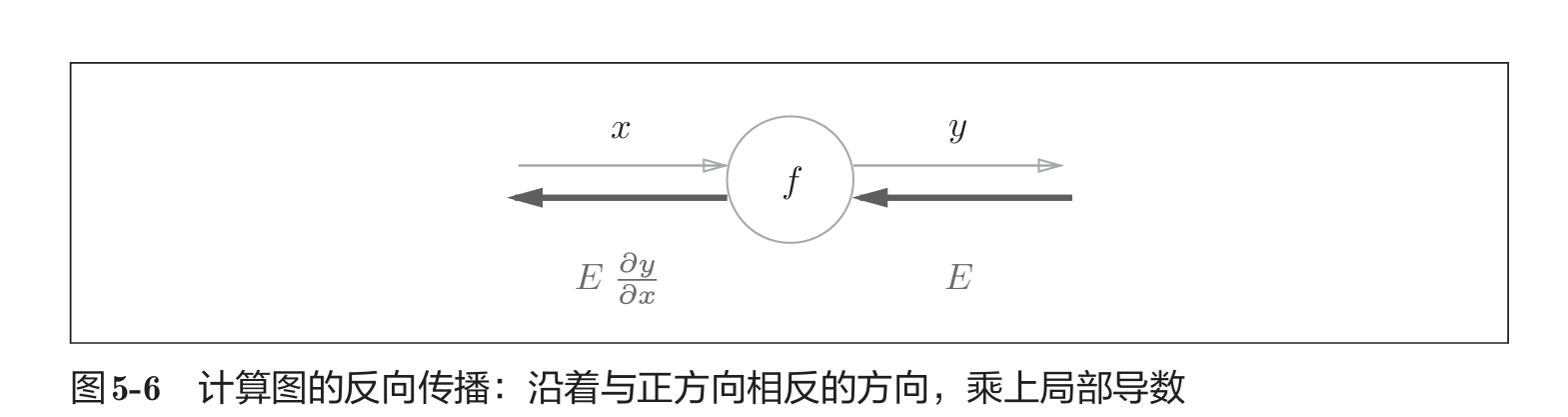
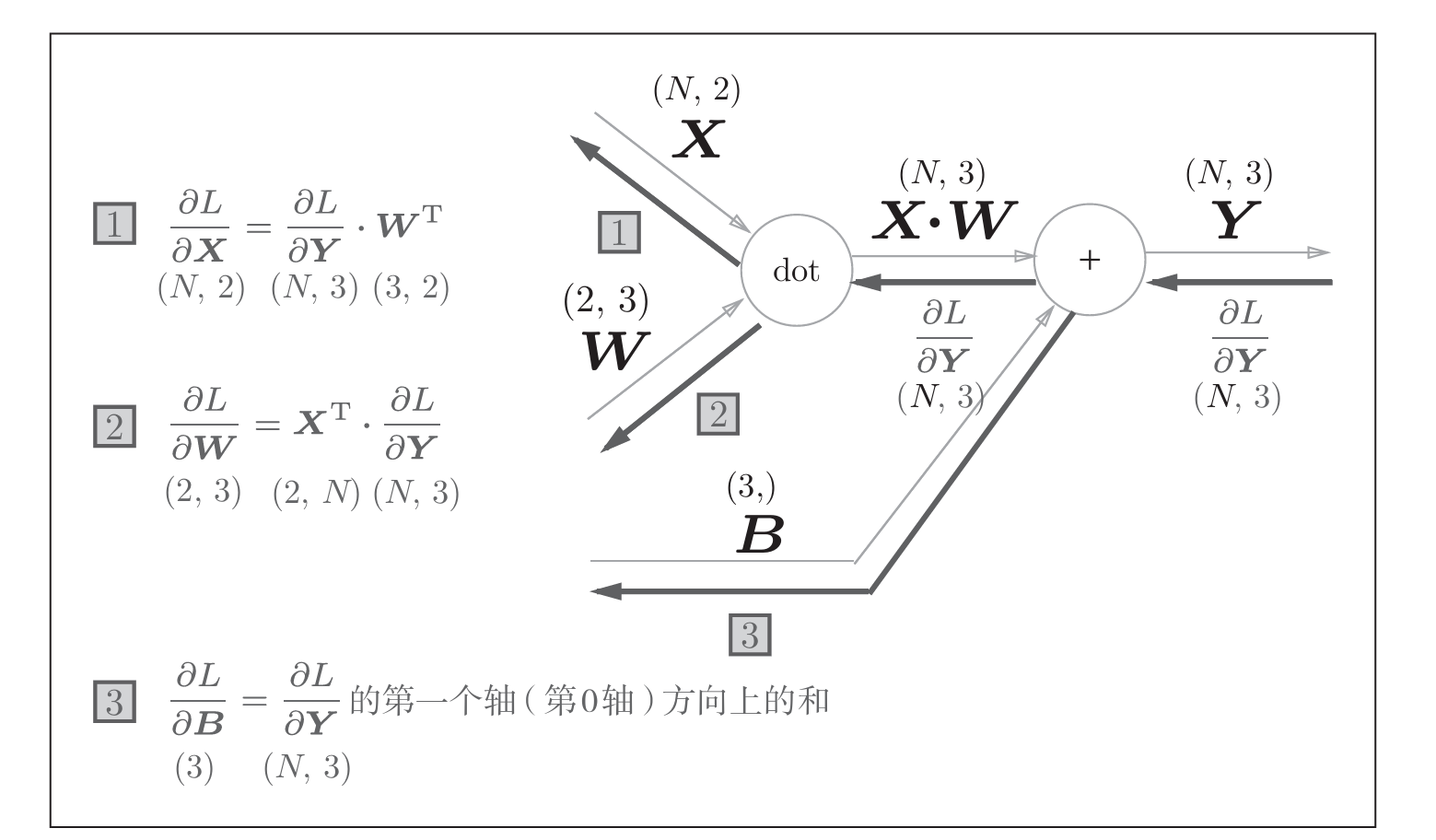
5.1.3 Affine层实现
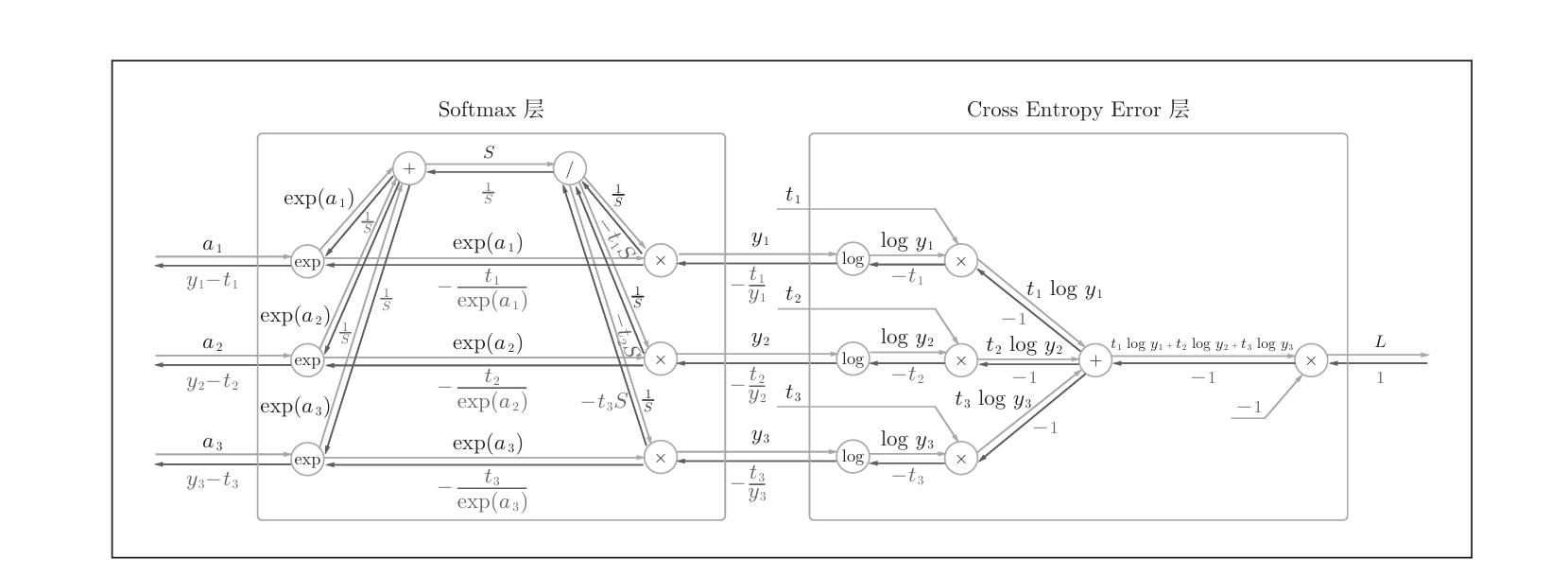
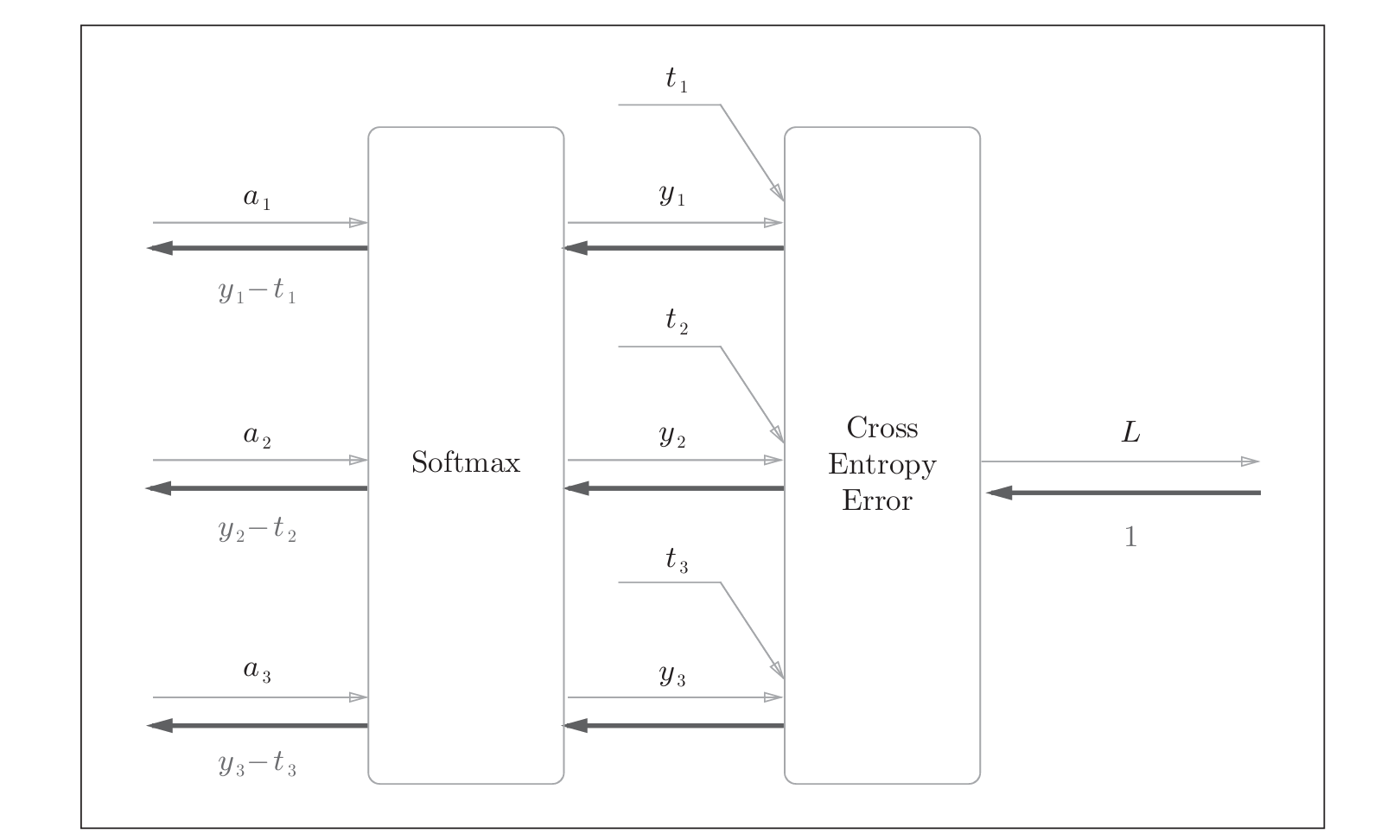
5.1.4 Softmax-with-Loss层
Comments NOTHING